







Data Lakes sind beliebte Komponenten von Cloud Data Plattform Architekturen. Wenn Du Dich für die Implementierung von Data Lakes und entsprechenden Services auf AWS interessierst, solltest Du folgende Blogbeiträge lesen. Bei einem Data Lakehouse handelt es sich um eine Architektur, die Datentransparenz im Data Lake ermöglicht und die Daten für die weitere Auswertung in einem Data Warehouse verfügbar macht. Erfahre hier mehr.
Im Rahmen spezifischer Kundenprojekte stoßen wir beim Aufbau eines komplett neuen Data Lakehouse häufig auf dieselbe Herausforderung – nämlich die Einhaltung des Datenschutzrechts. In dieser Blogreihe beschäftigen wir uns deshalb mit verschiedenen Aspekten der Datenschutz-Grundverordnung (DSGVO). Die europäische Verordnung betrifft den Schutz natürlicher Personen bei der Verarbeitung personenbezogener Daten und sieht unter anderem vor, dass Kund:innen das Recht auf Auskunft zu den von ihnen gespeicherten Daten sowie auf Löschung dieser Daten haben. Im ersten Teil 1 dieser Blogreihe erklären wir, wie wir sicherstellen können, dass personenbezogene Daten separat verarbeitet werden.
Die Vorteile eines generalisierten Frameworks
Im Folgenden beschreiben wir unser Architektur-Framework für das Data Lake eines Lakehouse auf AWS. Dieses Framework katalogisiert automatisch alle in den Data Lake eingehenden Daten und macht sie für die effektive und nutzbringende Analyse verfügbar. Die Implementierung dieser Architektur erfolgt als generalisiertes Framework. Auf diese Weise lässt sich ein gut strukturiertes und voll funktionsfähiges Out-of-the-Box-Lakehouse für Kundenprojekte schnell aufbauen. Gleichzeitig basiert unser Framework auf den Services, die man für ein AWS Data Lakehouse üblicherweise nutzen würde, damit der Kunde von seinem bereits vorhandenen Know-how im Bereich AWS Data & Analytics profitieren kann. Wir verwenden S3-Buckets für verschiedene Data-Lake-Layers, Glue Crawler zur Erstellung von Datenkatalogen und Glue Jobs, um die Daten entlang der Pipeline durch die einzelnen Data-Lake-Layer zu transferieren. Implementiert wird all dies mithilfe der AWS-Infrastructure-as-Code CDK (Cloud Development Kit).

Wie funktioniert das Framework?
Das obere Diagramm bietet eine Übersicht über unser Data-Lake-Framework. Im ersten Schritt (blauer Kasten) wird ein Datensample für einen Use Case in den S3 Config Bucket geladen. Dieser Bucket enthält die Dateien, die als Basis für die Config-Daten dienen. Wird eine neue Datei in den Bucket importiert, startet ein Glue Crawler. Dadurch wird unser Config-Datenkatalog mit den Schemata, Tabellen und Spalten für das Lakehouse gespeist. Für jede neue Datei wird im Datenkatalog eine Tabelle erstellt. Der nächste Schritt ist der einzig manuelle. Die verschiedenen Spalten im Config-Datenkatalog sind die zentralen Standorte für die Definition von Metadaten wie z. B. Primary Keys, personenbezogene Daten (PII) und Business Keys (siehe folgenden Screenshot).
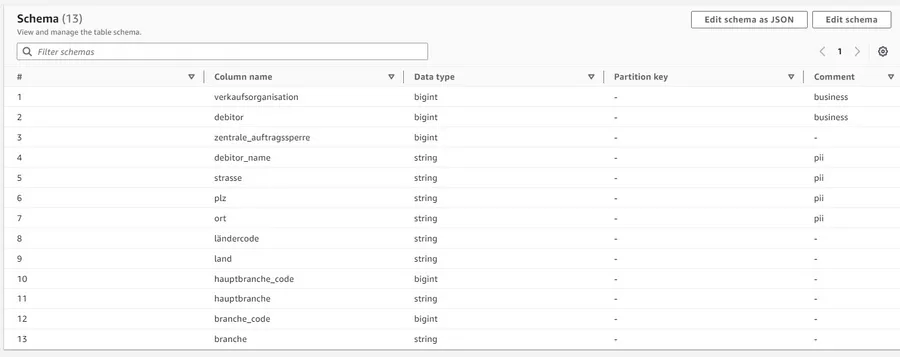
Die Metadaten werden uns beim ETL-Prozess noch hilfreich sein.
Wenn nun Daten im Landingzone Bucket eintreffen, setzt ein Trigger die Datenpipeline des Frameworks in Gang, um die Datei innerhalb der verschiedenen Data Lake Layer zu verarbeiten. Unsere erste Implementierung sieht lediglich die Stapelverarbeitung von CSV-Dateien vor; das Framework kann jedoch um weitere Dateiformate und Ingestion-Arten erweitert werden.
Im ersten Schritt der Datenpipeline wird ein Glue ETL-Script gestartet, um die Dateien in den Raw Bucket zu übertragen. Den automatischen Trigger haben wir als AWS-Lambda-Funktion implementiert. Mit Glue-Workflows bietet AWS jedoch eine weitere, kürzlich eingeführte Option, um die Pipeline zu starten. Die Metadaten aus dem Config-Datenkatalog wie Spaltennamen und PII-Datenspalten werden für notwendige dateispezifische Variablen im ETL-Script verwendet. Im Rahmen dieses Verarbeitungsschritts werden die Daten beispielsweise durch einen Ladezeitstempel angereichert und in ein spaltenorientiertes Dateiformat (Parquet) transformiert, um Daten effizient im Data Lake speichern zu können.
Sobald die Daten im Raw Bucket ankommen, löst eine Lambda-Funktion einen zweiten Glue-Job aus. In diesem Schritt werden die Metadaten aus dem Config-Datenkatalog auf separate PII-Daten aus nicht personenbezogenen Daten (non-PII) angewendet. Bei der Entwicklung des Frameworks haben wir uns entschieden, PII-Daten durch Separierung in zwei standardisierte Buckets zu verarbeiten – einen Bucket mit PII-Daten und den anderen mit Non-PII-Daten.
Im letzten Schritt starten wir Glue Crawler für die standardisierten Buckets und finalisieren damit den standardisierten Daten-Layer. Jetzt können ganz einfach alle erdenklichen Datenanalysen vorgenommen und Insights generiert werden. Bei Bedarf lassen sich zudem problemlos weitere Data-Model-Layer einbinden.
Geht es noch besser?
Um noch höhere Datenschutzstandards zu erfüllen, sollen PII-Daten in den kommenden Entwicklungsstufen des Frameworks verschlüsselt werden. Durch Verschlüsselung entsteht ein weiterer Security-Layer, da keine PII-Daten mehr unverschlüsselt gespeichert werden. Somit müssten sich Unbefugte nicht nur Zugriff auf die S3-Buckets verschaffen, sondern sie bräuchten auch den Schlüssel, um auf die Daten zugreifen zu können. Schließlich können weitere AWS-Services wie Macie integriert werden, um eingehende Daten in PII- und Non-PII-Daten zu kategorisieren.
Im zweiten Teil unserer Blogreihe erklären wir Dir, wie Du mithilfe von AWS Lake Formation ganz einfach definieren kannst, welche Nutzer:innen berechtigt sind, auf die Daten in den verschiedenen Buckets zuzugreifen.