







Die neue SaaS-Lösung von Microsoft hat das Potenzial, die Datenwelt zu verändern. Doch lohnt sich jetzt schon eine Migration? Wenn ja, wie geht man am besten vor? Lakehouse oder Warehouse? Und was muss man beim OneLake alles beachten? Wo sind aktuelle Hürden? Und was ist mit Azure Synapse?
Das alles möchten wir euch in diesem Beitrag zeigen.
Die wichtigste Nachricht für alle Azure-Synapse-Kunden zuerst: Synapse wird weiterhin voll unterstützt, ist nicht abgekündigt, und Microsoft hat auch keine Pläne, dies zu tun! Wo es sich dennoch lohnt, einen Blick in die Zukunft zu werfen, erfahrt ihr hier.
Microsoft OneLake
Bei der Integration und Weiterverarbeitung von Daten stellen Kopier- und Replikationsvorgänge einen erheblichen Aufwand dar, der sowohl erhöhte Kosten als auch längere Verarbeitungszeiten zur Folge hat. Zusätzlich führt dies oft zu verschiedenen Versionen derselben Daten, die verschiedene „Wahrheiten“ widerspiegeln.
Microsoft OneLake hat das Ziel, die Daten nur noch in einer Version vorliegen zu haben und Kopiervorgänge wo möglich zu vermeiden. Dazu wird OneLake als Speicher für verschiedenste Dienste und Tools über ein vereinheitlichtes Interface nutzbar gemacht.
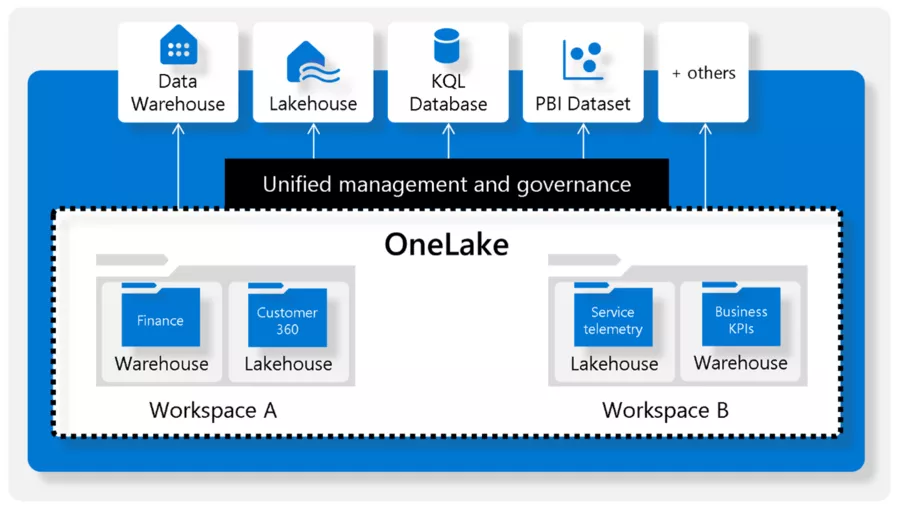
Mehr Details zum OneLake findet ihr unter diesem Link.
Fabric Lakehouse und Warehouse
Wenn es um die Migration von Data Warehouses geht, bietet Microsoft in Fabric zwei Dienste mit unterschiedlichen Einsatzmöglichkeiten an:
- Das Lakehouse: Der zentrale Datenspeicherort in Fabric. Daten können in einem Data Lake in beliebigen Dateiformaten gespeichert und weiterverarbeitet werden. Daten im DeltaLake-Format werden dabei als Tabellen dargestellt und können über die verschiedenen Abfragesprachen und Tools einfach weiterverarbeitet werden. Shortcuts ermöglichen es dabei, weitere externe Datenquellen (z. B. Azure Data Lake Storage Gen2, Amazon S3 oder auch andere Daten in OneLake) in diesem Tabellenformat zu lesen, ohne die Daten dafür in das Lakehouse kopieren zu müssen. Die Integration der Lakehouse-Artefakte in GIT ist nun ebenfalls möglich!
- Das Warehouse: Während das Lakehouse eine SQLOberfläche anbietet, ist diese read-only (vergleichbar mit Synapse SQL Serverless). Das Fabric Warehouse realisiert dagegen ein vollwertiges Data Warehouse (read & write). Es können Schemata, Tabellen und Stored Procedures angelegt und verwendet werden, ebenso wird das Deployment der DDL-Definition mittels SQLPackage unterstützt, wie gerade angekündigt wurde. Ein wichtiger Schritt auf dem Weg zur Automatisierung! Mittels OneLake können alle Delta-Lake-Objekte aus dem Lakehouse im Warehouse direkt abgefragt werden, was wiederum direkten Zugriff auf externe Datenquellen mittels Shortcuts erlaubt. Mithilfe dieser Technik ist es nun auch möglich, dezentrale Domänenkonzepte zu unterstützen.
Wie könnten jetzt die einzelnen Szenarien aussehen, um eventuell auch neue Workloads wie Data Science/AI oder IoT in Fabric zu realisieren?
Fall 1: Der Modern Data Estate
Wenn ihr bereits in der glücklichen Lage seid, ein Lakehouse mittels Azure Databricks oder Synapse Spark erstellt zu haben, dann habt ihr bereits die perfekte Ausgangslage. Mithilfe des Konzepts der Shortcuts (für die SQL-Leute unter euch: vergleichbar mit einem Linked Service) kann der bestehende Delta Lake direkt und ohne Umwege verwendet werden. Es besteht direkt die Möglichkeit, die Daten den vielen Compute Engines in Fabric (Data Science/IoT/Power BI etc.) zur Verfügung zu stellen, ohne die Daten kopieren zu müssen. (Wichtig: Es muss sich auch schon um einen Delta Lake handeln, ansonsten muss doch erst eine Umwandlung der Files erfolgen.)
Es gibt einen großen Vorteil, der damit sofort „gratis“ daherkommt: Power BI kann mit diesen Daten im Direct-Lake-Modus arbeiten. Was bedeutet das? Power BI greift damit ohne Umwege auf die Delta-Files zu, ohne dass die Daten erst via Semantic Model (früher: Dataset) importiert werden müssen. Zusammengefasst: Man erhält die Performance vom Import-Modus kombiniert mit der Aktualität von DirectQuery ... und man spart sich die Zeitplanung für das Semantic Model aka Dataset.
Aufbauend auf diesem Shortcut-Konzept wäre es nun auch möglich, die SQL Dedicated Pools zu migrieren und diese entweder als Lakehouse oder Warehouse in Fabric weiterzuführen.
Mögliche Schritte:
- Exportieren des Dedicated SQL Pools in ein SQL-Projekt und Import dieses Projekts nach Fabric
- Es gibt mittlerweile PowerShell-Scripts auf GitHub, die die Konvertierung von SQL Dedicated Pool DDLs zu Fabric DDLs unterstützen.
Für 2024 wurde ebenfalls ein Migrationsassistent angekündigt, der sogar in der Lage sein soll, die Endpunkte automatisch umzuleiten.
Welches Tool hier eventuell noch unterstützen kann, erfahrt ihr später!
Was ist mit der Azure Data Factory? Jetzt, wo Microsoft Fabric allgemein verfügbar ist, sind auch die Fabric Pipelines allgemein verfügbar, und damit sind die meisten Aktivitäten rund um die Orchestrierung bereits vollständig unterstützt. Die ADF kann nun auch direkt nach OneLake schreiben und verringert damit den Migrationsaufwand erheblich.
Es bleibt allerdings dabei: Auch zum aktuellen Zeitpunkt gibt es keine Mapping Dataflows aus der ADF in Microsoft Fabric. Das bedeutet, dass die bestehenden Dataflows entweder durch Dataflows Gen2 in Fabric ersetzt werden müssen (verfügbarer Guide: https://aka.ms/datafactoryfabric/docs/guideformappingdataflowusers) oder der Mapping-Dataflows-Code durch Spark-Code konvertiert werden muss. Auch hierzu hat das Fabric Customer Advisory Team (Fabric CAT) Tools bereitgestellt: https://github.com/sethiaarun/mapping-data-flow-to-spark.
Ab jetzt werden für die Dataflows Gen2 auch VNet Data Gateways unterstützt, so dass nun die Integration in bestehende Netzwerkinfrastrukturen funktioniert!
Ein Punkt, der ebenfalls bekannt gegeben wurde: Es wird im zweiten Halbjahr 2024 die Möglichkeit geben, eine bestehende Azure Data Factory in Fabric zu „mounten“. Das Prinzip kennen wir schon von den SSIS-Workloads damals.
Fall 2: Migration einer SQL Managed Instance
Wie aber heben wir unsere beispielsweise in einer SQL Server Managed Instance bestehenden DWH-Prozesse nun auf Fabric?
Durch die Unterstützung von SQLPackage Deployments können ab sofort alle so bereits definierten Objekte einfach nach Fabric migriert werden. Wie kann man aber nun die Daten mit dem geringsten Aufwand initial nach Fabric laden?

Wir haben das einmal anhand der Beispieldatenbank AdventureWorks 2022 durchgespielt:
- Zunächst legen wir in Fabric ein Lakehouse und Warehouse an, binden das Lakehouse in der SQLMI als externe Datenquelle an und exportieren die bestehenden Tabellen als Parquet-Dateien (vgl. Blog von Jovan Popovic).
- Mittels Spark Notebook konvertieren wir diese in das Delta-Format, damit sie als Lakehouse-Objekte bereitgestellt werden können.
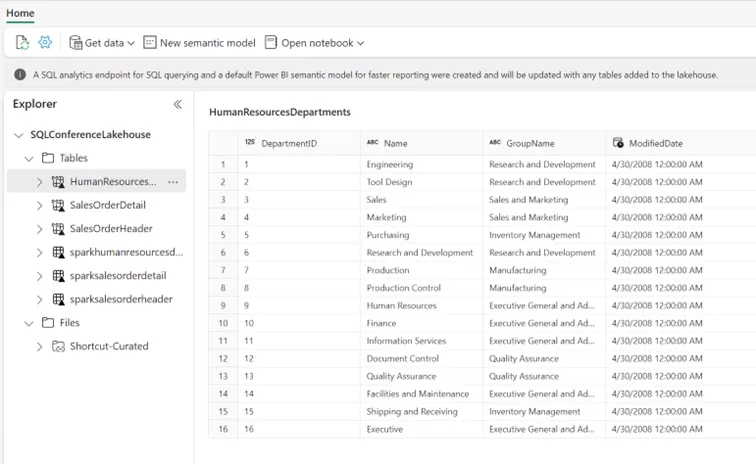
Im Warehouse können wir sie direkt verwenden oder (beispielsweise als Stage-Tabellen) weiterverarbeiten. Prozeduren müssen eventuell angepasst werden, um das Lakehouse korrekt zu referenzieren (entsprechend einer datenbankübergreifenden Abfrage auf einem SQL Server).
- Als Beispiel haben wir hier ein Prozedere verwendet, um Daten in die Departments-Tabelle zu schreiben.
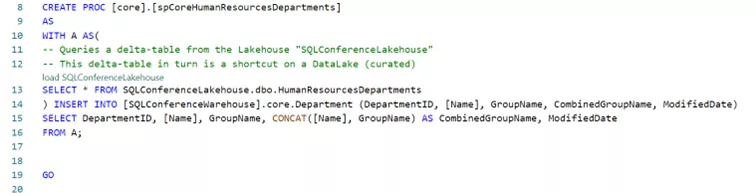
Diese neuen Tabellen können wiederum über klassische SQL-Interfaces oder direkt in Power BI weiterverwendet werden. Auch neu: Fabric Warehouses unterstützen ab sofort den Direct-Lake-Modus in Power BI, so dass wir auch hier mit einer Reduzierung der Komplexität der zukünftigen Lösung rechnen können.
Auf dem Weg zu einer Migration gibt es noch zwei weitere Techniken/Tools, die ab jetzt verfügbar sind:
dbt-Fabric
dbt wird mittlerweile in vielen Data-Warehouse-Szenarien verwendet, um Datenintegrationen zu definieren und zu testen und diese ohne Stored Procedures auszuführen.
Während bestehende SQL-Lösungen meistens auf Community-Konnektoren basieren, hat Microsoft direkt mit Fabric einen Konnektor für dbt entwickelt. Es ist der Anspruch der Entwickler:innen, stets alle Artefakte, die Fabric Warehouse unterstützt, auch im dbt-Konnektor zu unterstützen. Sollte ein bestehendes Warehouse (z. B. Microsoft SQL Server/Snowflake oder Amazon Redshift) bereits in einem dbt-Projekt vorliegen, kann dieses leicht nach Fabric überführt werden. An dieser Stelle sollte man stets darauf achten, datenbankspezifische SQL-Dialekte im Vorfeld zu bereinigen. Beispielsweise wird gerade erst sp_rename im Fabric Warehouse unterstützt.
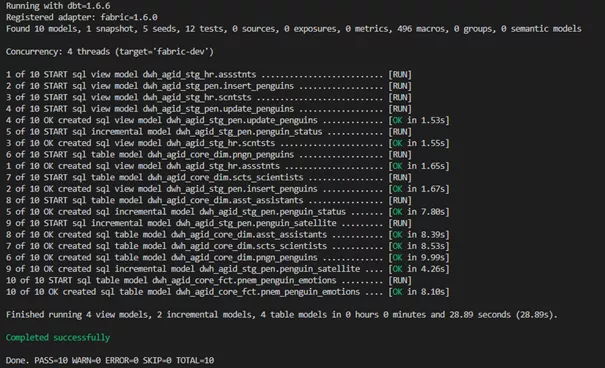
Ergebnis in Fabric Warehouse:
Mirroring
Ganz neu in Microsoft Fabric: Mirroring – doch was bedeutet das konkret?
Unter diesem Begriff versteht Microsoft eine Real-time Data Replication mittels Change Data Capture (CDC) in One Lake, um dort weitere Anwendungsfälle zu ermöglichen und die Daten aus den operativen Systemen zur Verfügung zu stellen. Die gespiegelten Daten lassen sich über alle Endpunkte abfragen. Das bedeutet, dass man auf diese Daten sofort mittels T-SQL-Abfragen zugreifen und sie mit Daten aus dem bestehenden Warehouse joinen kann (via Shortcuts).
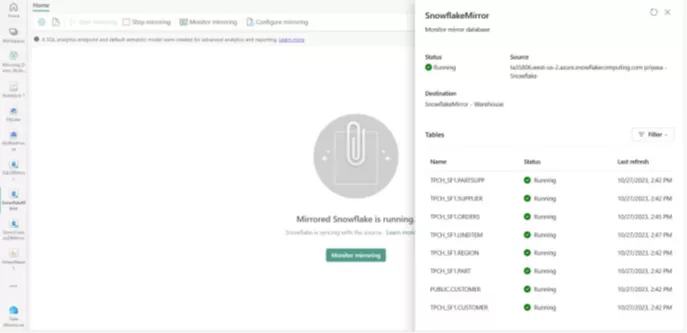
Mirroring ist derzeit für Azure Cosmos DB, Azure SQL DB und Snowflake verfügbar. Für Snowflake wird diese Funktion ganz besonders spannend. Das Spiegeln der Datenbanken bedeutet nämlich auch, dass man den Workload auf einer Snowflake-Datenbank (und damit die Kosten) massiv reduzieren und das Reporting (also die Ad-hoc-Abfragen, die durch Power BI generiert werden) über den Spiegel direkt mit dem Direct-Lake-Modus in Power BI durchführen kann. Der End User muss also nur die Verbindung „tauschen“ und kann sofort die neuen Möglichkeiten nutzen und die Daten für viel mehr Usergruppen erschließen, ohne sich großartig um die Technik kümmern zu müssen.
Der nächste Schritt könnte dann, wie oben beschrieben, die eigentliche Migration mittels dbt sein.
Abschließend hier noch eine mögliche Architektur-Lösungsskizze, die alle eben beschriebenen Wege enthält:
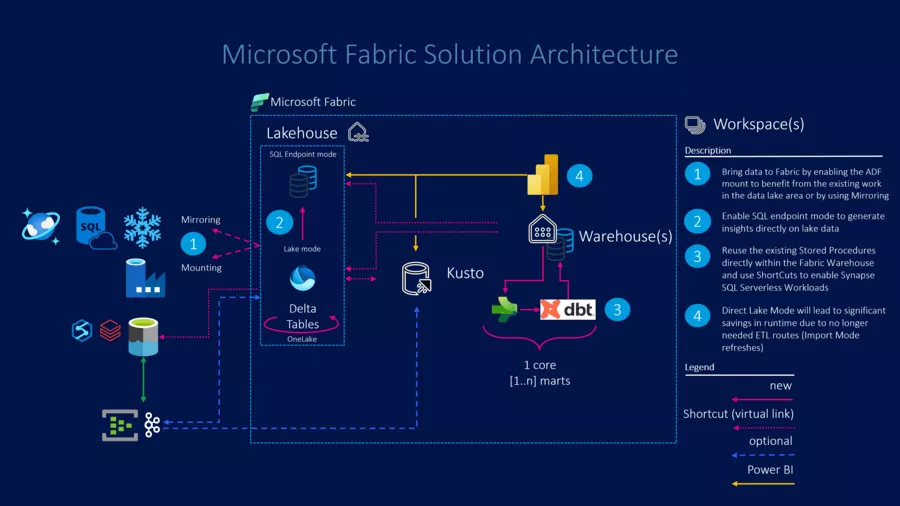
Interesse geweckt? Haben wir etwas übersehen? Dann wende Dich an eine:n unserer vielen Azure-Expert:innen für einen ersten unverbindlichen Beratungstermin, damit wir Dir helfen können, Dich in Microsoft Fabric zurechtzufinden!