







Allgemeine Anforderungen der Unternehmen
Viele Unternehmen mit SAP-Quellsystemen kennen diese Herausforderung: Sie wollen ihre Daten in einen Azure Data Lake integrieren, um sie dort mit Daten aus anderen Quellsystemen und Applikationen für Reporting und Advanced Analytics weiterzuverarbeiten. Auch die neuen SAP-Informationen zur Nutzung des SAP-ODP-Frameworks führten bei b.telligent Kunden zu Fragen. In diesem Blogbeitrag stellen wir drei gute Ansätze zur Datenintegration (in die Microsoft Azure Cloud) vor, die wir bei b.telligent empfehlen und die von der SAP unterstützt werden.
In Teil 1 fassen wir die Anforderungen der Kunden zusammen.
In den meisten Fällen wollen die Unternehmen ihre SAP-Daten in den Data Lake integrieren, um sie in Big-Data-Szenarien und für Advanced Analytics weiterzuverarbeiten (meistens auch verknüpft mit Daten aus anderen Quellsystemen).
Die wichtigste Anforderung ist selbstverständlich, dass es keine Performance-Probleme oder Ausfälle des Quellsystems gibt. Also darf das Quellsystem zu keiner Zeit überlastet werden. Vielen Unternehmen genügt es, dass Daten bis zum Vortag für Reporting und Analytics zur Verfügung stehen. Nur in seltenen Fällen muss eine schärfere Aktualität der Daten gewährleistet werden. Somit genügt es meistens, per Daily-Batch-Jobs täglich die neusten Daten in den Data Lake zu laden.
Um die Datenmenge, Kosten und Systemlast deutlich zu reduzieren, sollten die Daily-Loads im Idealfall nicht täglich alle relevanten Tabellen vollständig lesen. Je nach Quellsystem kann dieses Thema im Detail jedoch eine Herausforderung sein. Eine der wichtigsten Anforderungen auf Business-Seite besteht meist darin, dass die Daten spätestens zu Bürozeiten für Reportings zuverlässig und performant zur Verfügung stehen. Deshalb ist es wichtig, dass die Jobs idealerweise nachts mit ausreichend Puffer durchgeführt werden.
Aus IT-Sicht ist eine wichtige Anforderung, dass die Lösung gut wartbar und erweiterbar ist. Dafür braucht es ein transparentes Monitoring für die Jobs und automatisiertes Alerting. Im Detail kann es bedarfsweise weitere technische Anforderungen geben, beispielsweise im Bereich Datenspeicherungsformat und Partitionierung.
Allgemeine Übersicht der Lösungsvorschläge
Im Jahr 2024 gab es im Hinblick auf unser SAP-Daten-Extraktionsszenario eine wichtige Aktualisierung des SAP-Hinweises 325574, die unsere Kunden verständlicherweise beunruhigt. Die neue Richtlinie besagt, dass die Verwendung der RFC-Module der Operational Data Provisioning (ODP) Data Replication API durch Kunden- oder Drittanwendungen für den Zugriff auf SAP-ABAP-Quellen nicht mehr erlaubt ist. Um unseren Kunden ihre Sorgen zu nehmen, können wir drei smarte Lösungsvarianten anbieten, die von der SAP weiterhin unterstützt und bei Kunden häufig für die Integration der SAP-Daten verwendet werden. Welche Variante die jeweils „richtige“ ist, hängt wie bereits erwähnt von der Ausgangslage und den Anforderungen auf Kundenseite ab. In folgender Übersicht sind die drei Varianten mit ihren Kerneigenschaften dargestellt:
SAP Datasphere
Datasphere ist ein SaaS-Cloud-Service der SAP-Business-Technology-Plattform zur Sammlung und Bereitstellung von Unternehmensdaten. Sie spielt mit ihren Möglichkeiten zur Modellierung, Anbindung und Virtualisierung von SAP- und Nicht-SAP-Daten eine zentrale Rolle in der aktuellen SAP-Datenmanagement-Strategie.
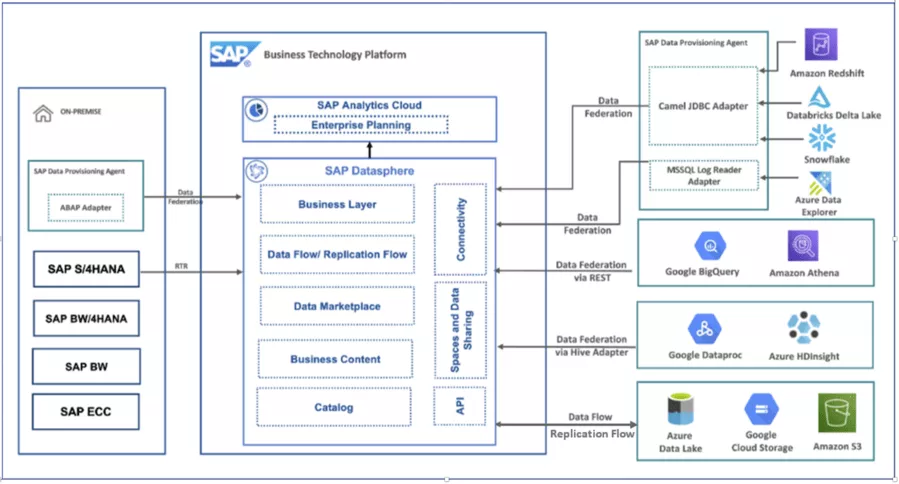
Abbildung 1: Solution-Diagramm Datasphere; Referenz: SAP Discovery Center Mission - Explore your Hyperscaler data with SAP Datasphere (cloud.sap)
Die sogenannte „Premium Outbound Integration“ ist der präferierte und empfohlene Weg der SAP, um SAP-Daten in einen Data Lake zu transferieren. Mit Hilfe von Replication Flows lassen sich SAP-Quelldaten CDC-fähig an die Datasphere anbinden und direkt im Data Lake als Parquet-Files zur Verfügung stellen. Dabei werden auch deltafähige CDS-Views als Quelle unterstützt.

Abbildung 2: Connectivity Options SAP Datasphere Replication Flows
Für Details zur Nutzung von Replication Flows siehe auch Replication Flow Blog Series Part 2 – Premium Outb... - SAP Community.
Ein klarer Vorteil dieser Lösung ist, dass sie der aktuellen SAP-Strategie für solche Szenarien folgt und so auch künftiger SAP-Support zu erwarten ist. Die Integration der Datasphere mit SAP-Quellen ist bereits gut unterstützt und wir können weitere Innovationen erwarten, beispielsweise bezogen auf die Interaktion mit Hyperscalern und SAP-Partnern. Die Datenladezeiten sind bei dieser Option im Vergleich eher gut. Ein weiterer Pluspunkt: Die CDS-Views als semantischer Layer sind bereits im standardmäßig ausgelieferten Business Content integriert. Falls nötig können die Daten bei der Extraktion oder anschließend in der Datasphere transformiert beziehungsweise modelliert werden. Auch hier gibt es bereits ausgelieferten Business Content.
Die Kosten für den Datasphere Service folgen, wie generell in der Business-Technology-Plattform, einem Subscription-Modell. Zu beachten ist außerdem, dass die Orchestrierung der Datenextraktion und -bereitstellung über die Datasphere stattfindet, wir also aus Azure-Sicht mit einem Push-Prinzip arbeiten. Je nach Unternehmensorganisation entsteht hier potenziell ein Übergang der Verantwortlichkeiten (SAP – Azure).
Azure Data Factory
Das Microsoft-Produkt Azure Data Factory ist eine Azure-Lösung für die Batch-Integration von Quellsystemdaten. Die Lösung bietet Konnektoren für viele verschiedene Quellsysteme, unter anderem SQL-Server, Oracle, Dataverse und SAP. Für SAP stehen verschiedene Basis-Konnektoren zur Auswahl (beispielsweise SAP-Table, SAP-HANA und SAP-CDC). Die Konnektoren unterscheiden sich durch den Zugriff auf die Daten (Zugriff auf ABAP-Layer oder direkt auf HANA-DB) und dementsprechend gibt es auch Unterschiede in den erforderlichen Lizenzvereinbarungen, den Funktionalitäten und der Performance. Bevor wir auf die konkreten Unterschiede der einzelnen Konnektoren eingehen, gilt es kurz zu beschreiben, wie diese Konnektoren genutzt werden können:
Die Konnektoren werden über Parameter gesteuert, die im User Interface der Azure Data Factory definiert werden können. Grundsätzlich gilt es, über die Parameter entsprechende Verbindungsdetails zum Quellsystem zu definieren, wie beispielsweise die Quellsystem-Adresse, User und Credentials, aber auch Angaben zum Ziel des Transfers und in welchem Dateiformat die Daten gespeichert werden sollen.
Auf Tabellenebene muss angegeben werden, welche Tabelle gelesen werden soll. Im Detail lassen sich noch weitere Parameter steuern, wie beispielsweise die Partitionierung oder die Insert-Art beim Schreiben der Daten. Der Datenabzug über die Konnektoren kann dann über die ADF-Pipelines organisiert und orchestriert werden.
Es ist nicht ratsam, die Parameter der Konnektoren über hartcodierte Werte pro Tabelle manuell zu definieren. Deshalb hat b.telligent ein eigenes Metadaten-Framework aufgebaut, um die Konnektoren sinnvoll zu nutzen. Ziel ist es, dass die Konnektoren die oben genannten Parameter nicht hartkodiert im Bauch haben, sondern aus einer Konfig-Metadaten-Tabelle gelesen werden. Die Secrets für den Zugriff auf die Quellsysteme werden dabei aus dem Key-Vault gelesen. Durch dieses „Metafactory“-Framework kann die Datenintegration bei Bedarf einfach und sicher um weitere Tabellen erweitert werden. Braucht das Business beispielsweise eine weitere SAP-Tabelle zu Reporting-Zwecken, kann ein interner Entwickler die Metadaten-Tabelle entsprechend erweitern.
Wie bereits erwähnt stehen in der ADF unterschiedliche SAP-Konnektoren zur Auswahl. Wir gehen nun auf die wesentlichen Unterschiede der ADF-SAP-Konnektoren ein, konkrete Details können der Dokumentation von Microsoft entnommen werden.

Abbildung 3: Übersicht der Azure-Data-Factory-Konnektoren
Mit Azure Data Factory (ADF) haben wir sehr gute Erfahrungen gemacht. Wir haben bereits mehrere produktive Pipelines mit den ADF-Konnektoren aufgebaut. Ein großer Vorteil ist, dass ADF nicht nur SAP-Konnektoren bietet, sondern auch viele andere Datenquellen angebunden werden können. So kann im Unternehmen ein einheitlicher Datenintegrationsprozess implementiert werden.
In Bezug auf Performance und Stabilität konnten wir die Kernanforderungen erfüllen und haben, bei üblichen Rahmenbedingungen, gute Erfahrungen gemacht – wenn die Lösung richtig implementiert wurde. Allerdings gibt es auch Nachteile, insbesondere bei der Benutzerfreundlichkeit für Entwickler im SAP-Kontext. Zum Beispiel kann man bei manchen Konnektoren aus der ADF nicht abfragen, wie viele Zeilen eine Tabelle hat, und Informationen zu den Feldern der SAP-Tabellen sind ebenfalls nicht abrufbar. Das ist vor allem bei der Planung von Initial-Loads mühsam, weil man die Größe der Tabelle vorab richtig einordnen sollte. Wir raten hier zu einer engen Zusammenarbeit mit den Entwicklern, die über das nötige SAP-Quellsystem-Wissen verfügen, um bei Bedarf an die entsprechenden Informationen aus dem Quellsystem zu kommen.
Ein weiterer Punkt ist, dass die aktuellen ADF-Konnektoren kein Change Data Capture (CDC) erlauben (Stand Oktober 2024). CDC ist aber oft wichtig, um bestimmte SAP-Tabellen inkrementell zu laden, insbesondere wenn keine eindeutigen fachlichen Zeitstempel oder IDs für ein sauberes inkrementelles Laden zur Verfügung stehen. Es sollte deshalb unbedingt geprüft werden, ob alle Tabellen auch ohne im Konnektor angebotenes CDC geladen werden können, bevor ein ADF-Konnektor verwendet wird.
Drittanbieter
Unter den Drittanbietern ist Theobald Software aus Stuttgart das wohl bekannteste und auch meistgenutzte Tool in Deutschland. Deshalb gehen wir an dieser Stelle näher auf dieses Tool ein. Generell gibt es eine Reihe an Drittanbieterlösungen, die wir in einem der folgenden Blogs betrachten wollen.
Theobald Software hat zwei Hauptprodukte, um Daten aus SAP zu extrahieren: XtractUniversal (XU), eine Stand-alone-Lösung, sowie ein Add-on Xtract IS (for Azure) für die SQL Server Integration Services (SSIS) von Microsoft.
1. XtractUniversal (XU) stellt das jüngere Produkt dar und besteht aus einem Application Server, der die Extraktionen ausführt, und einem GUI, dem XU-Designer, mit dem man ohne zu programmieren die Extraktionen anlegt, inklusive der Destinations. Der Designer liefert folgende Funktionalitäten:
- Suchfeld zum Suchen eines SAP-Objektes
- Metadaten zu den Spalten, wie Description, Primary Key etc.
- Filtermöglichkeiten
- Row Count und Row Preview der Daten
- Zugriffsbeschränkungen
- Log-Viewer
Die Extraktionen können entweder manuell via Designer oder über einen Kommandozeilen-Aufruf respektive API Call ausgeführt werden. Letzteres bietet die Möglichkeit, die Steuerung der Extraktionen (zeitlich und parallel/seriell) in einem Metadaten-Framework aller Cloudanbieter zu hinterlegen. Als Ziel (Destination) einer Extraktion stehen dabei alle bekannten Datenbanken beziehungsweise Blob-Storages zur Verfügung. Darüber hinaus gibt es auch noch Pull-Destinations, wie beispielsweise PowerBI-Connector.
2. XtractIS (for Azure) ist ein Add-on für die SQL Server Integration Services (SSIS), um SAP-Daten als Quelle eines Dataflow nutzen zu können. Das bedeutet, dass dieses Produkt nur zusammen mit SSIS funktioniert. Es ist das ältere Produkt und wird in der Weiterentwicklung nachrangig behandelt. Neuere Features oder Komponenten gelangen also zuerst in das Produkt „Xtract Universal“ und werden dann später hier integriert. Die jeweiligen Interface-Komponenten haben die gleichen Funktionalitäten wie der XU-Designer. Nur das Logging muss über die SSIS selbst abgewickelt werden, siehe oben. Damit dieses Produkt in der Azure Cloud funktioniert, muss die SSIS IR verwendet und customized werden.
Diese Lösung eignet sich gut für Lift&Shift-Szenarien, aber auch für Neuentwicklungen, wenn man keinen Application Server zur Extraktion benutzen möchte. Die SSIS sind eine Extension des Visual Studios und können daher kostenlos zur Entwicklung genutzt werden. Hier ist man aber an Microsoft beziehungsweise SSIS gebunden.
Mögliche SAP-Extraktionsobjekte beider Produkte sind transparente Tabellen, Cluster-Tabellen und Views, die alle gefiltert und parametrisiert werden können. Die TableCDC-Komponente erlaubt den Delta-Abzug einer Tabelle, wenn kein Delta anhand einer bestimmten Spalte festgemacht werden kann. Die ODP-Komponente wiederum erlaubt den Abzug aller Objekte, die über ODP seitens SAP zur Verfügung gestellt werden. Diese Komponente ist aber aktuell nicht zu empfehlen. In Zukunft wird sie aber mit einer ODATA-Variante angeboten werden, um der Release Note 3255746 von SAP gerecht zu werden. Weitere Extraktionsobjekte sind BAPI, RFC-Funktionsbausteine, SAP ERP Queries, SAP Data Sources, SAP CDS-Views, BW/4HANA-Objekte, BW-Hierarchien via Open Hub Services sowie Cube-Objekte aus BW/BW HANA und ABAP-Reports.
Version Control/Deployment
Sowohl das Produkt XU als auch die Solution (Visual Studio) [SSIS mit Extension XtractIS] kann mit Version Control wie Git oder DevOps verbunden werden und die Lösung kann so in unterschiedlichen Umgebungen bereitgestellt (deployt) werden.
Lizenzkosten
Für beide Produkte fallen Lizenzkosten an. Die Lizenzkosten entsprechen einem Abonnement-Modell (Subscription). Das bedeutet, dass man für einen jährlichen Betrag Updates und Support von Theobald nutzen kann.
Einzelne Komponenten
Hier ist eine Liste der einzelnen Komponenten, mit denen man auf die entsprechenden SAP-Objekte zugreifen kann:

Abbildung 4: Übersicht über die Theobald-Konnektoren
Fazit und abschließende Bewertung
Wir haben im Blogbeitrag drei verschiedene Ansätze zum Transfer von SAP-Daten in die Azure-Cloud beleuchtet. Prinzipiell sind die Lösungen mit den Theobald- und ADF-Konnektoren sehr ähnlich.
Im Detail bieten die Theobald-Konnektoren eine etwas bessere Usability und Zusatzfunktionalitäten. Dafür fallen für die Nutzung von Theobald Lizenzkosten an und in der Architekturlandschaft braucht man entsprechende VMs.
SAP Datasphere ist die offizielle Empfehlung der SAP zum Export von SAP-Daten, also kann hier mit weiteren Innovationen und SAP-Unterstützung gerechnet werden. Es gilt jedoch zu erwähnen, dass nicht alle Unternehmen Datasphere im Einsatz haben, was wiederum SAP-Know-how für die Implementierung erfordert. Zudem kann eine Verantwortungsübertragung im Gesamtprozess entstehen. (Details im Kapitel „Datasphere“.)
Und nun schließt sich der Kreis. Die Wahl der besten Lösung hängt entscheidend von der Situation des Kunden ab. Einfache Szenarien mit kleinen bis mittleren Datenmengen und geringen Anforderungsänderungen brauchen sicher andere Varianten als hochkomplexe Szenarien.
Du hast die gleiche Herausforderung?
Falls Du ebenfalls vor der Herausforderung stehst, SAP-Daten in einen Cloud Data Lake zu integrieren, melde Dich gern bei uns. Unsere Expert:innen unterstützen Dich freundlich und kompetent mit dem entsprechenden Know-how!