







Learn how to extend AWS Redshift capabilities with minimal complexity by using Lambda, Fargate, and SQS.
Challenge
Extending Redshift’s capabilities while minimizing system complexity.
- Solution 1: Implementing basic AWS Lambda for straightforward tasks.
- Solution 2: Enhancing compute power via AWS Fargate for intensive workloads.
- Solution 3: Speeding up processes with parallel computation using AWS SQS and decoupled Lambda functions.
- Outcome: Architecture overview and guidelines to choose the best option for your needs.
Why use AWS Compute Services for Redshift?
Amazon Redshift comes with a robust set of capabilities right out of the box, making it an excellent choice for data warehousing. Its high performance, scalability, and user-friendly interface are key advantages that allow teams to efficiently manage large volumes of data. However, as data needs become more complex or specific, there may be situations where Redshift’s native capabilities need to be extended by leveraging additional AWS services for greater compute power and flexibility.
For teams operating a data warehouse in Redshift, especially those with limited resources, it's crucial to enhance the platform's potential without introducing unnecessary complexity. In this post, our primary goal is to build on Redshift's inherent strengths while integrating it with AWS services that offer greater flexibility—particularly in terms of programming languages and their associated libraries. This integration allows for a wide range of tasks to be executed directly within Redshift. Examples include alerting, advanced statistical analyses and delivering data to consumers outside of the AWS account.
Given that the team in our scenario is small and has limited resources, the emphasis is on maintaining simplicity—ensuring that all operations can be managed from within Redshift using SQL.
At a high level, we've identified three potential architectural approaches. To assess and compare the effectiveness of each option, we'll consider several key criteria:
1) The ease of integration with Redshift
2) The flexibility in terms of compute and language support
3) The complexity of the added infrastructure
4) The direct costs involved
Option 1: Lambda Integration via UDFs
The first architectural option involves integrating AWS Lambda with Redshift using User-Defined Functions (UDFs). This approach is particularly appealing due to the ease with which Lambda UDFs can be registered and integrated directly into Redshift. By allowing synchronous function calls, this setup makes it convenient to orchestrate various tasks directly from within Redshift. For example, you could generate an Excel report from data stored in Redshift and send the file via email to a business user or execute simple statistical analyses on time series data. For the latter, e.g. you could leverage Python libraries that are not available within Redshift by unloading data to S3, importing the libraries and conducting analyses with Lambda and copying the results back into Redshift.
Pros
- Ease of Integration with Redshift: Lambda UDFs can be seamlessly integrated into Redshift, allowing for synchronous function calls that make orchestration straightforward.
- Flexibility: Lambda provides a long list of environments and the option to deploy Docker containers that can be configured as needed.
- Minimal Additional Services: This approach requires minimal additional services beyond Lambda, keeping the architecture simple and focused.
- Costs: Lambda is one of the cheapest services on AWS. For instance, an invocation with the maximum configurable compute costs around 1 cent per minute runtime.
Cons:
- Compute Power and Memory Limitations: Lambda’s compute power is inherently tied to its memory allocation, which can be restrictive for more demanding tasks.
- Runtime Constraints: Lambda functions have a maximum runtime limit, which may not be sufficient for more complex or long-running operations.

Solution 1
However, while Lambda UDFs offer simplicity and straightforward integration, they come with certain limitations. These include constraints on compute power, as Lambda functions are coupled with limited memory, runtime, and storage integration. This makes them less suitable for tasks that require extensive computation or long-running processes.
Option 2: Fargate for Enhanced Compute
The second architectural option leverages AWS Fargate to provide additional compute power, offering a more scalable and flexible solution compared to Lambda. Fargate allows you to run containers without having to manage the underlying infrastructure, making it a powerful choice for tasks that require more computational resources.
In this setup, Redshift integration is achieved through an external Lambda UDF, which acts as an intermediary between Redshift and the Fargate service. This integration is completely transparent to Redshift users, meaning they can initiate tasks without needing to interact directly with Fargate. The advantage here is that users can continue to operate within Redshift using SQL, while Fargate handles the more compute-intensive processes behind the scenes.
Pros:
- Complete Flexibility: Fargate offers full flexibility with Docker images, allowing you to customize environments with the necessary languages, frameworks, and libraries for your specific use cases.
- Scalability: It’s easy to scale up resources on Fargate, making it a natural upgrade path when your computational needs exceed Lambda’s limitations.
- Seamless Integration: The integration with Redshift remains seamless and transparent, with users unaware of the switch from Lambda to Fargate.
Cons:
- Added Complexity: Using Fargate introduces additional complexity, particularly in managing the image registry and deployment processes. This requires more setup and operational oversight compared to the simpler Lambda-based approach.
- Runtime limit still restricted by Lambda: As a synchronous call to an external Lambda UDF is orchestrating the Fargate task, the runtime limit of 15 minutes still applies.
- Costs: The solution incurs additional cost due to the Fargate task. Running a task on Fargate, however, is, depending on required compute resources, potentially even cheaper than a long-running lambda function.
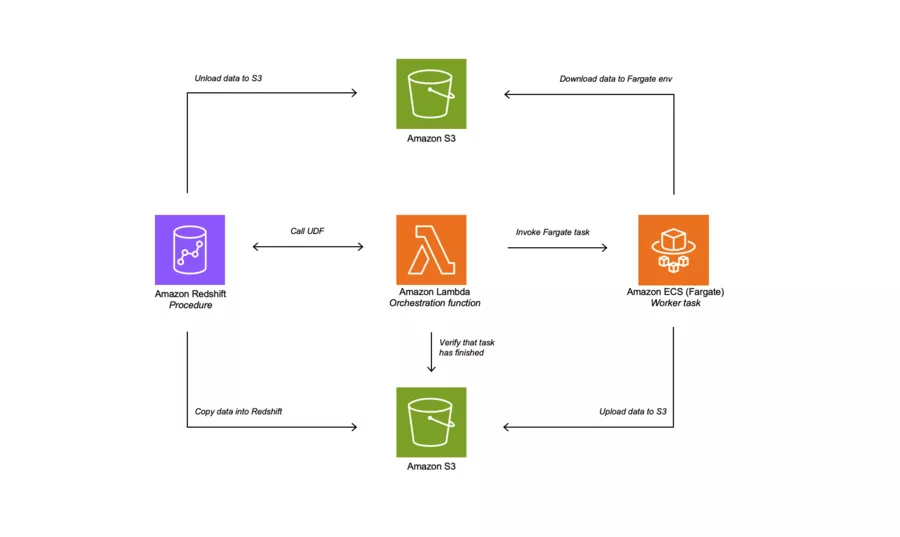
Solution 2
The combination of added complexity to implement AWS Fargate and the Lamda runtime limits for synchronous function limits make this option less interesting for most cases. However, it’s useful to keep it in mind to contrast option 1 and 3 with it.
Option 3: Parallel Lambda Execution with SQS
The third architectural option explores the use of parallel Lambda execution in combination with Amazon SQS (Simple Queue Service) to handle tasks requiring high horizontal scalability. This approach is particularly beneficial when your task can be run on multiple Lambda functions concurrently, leveraging the built-in concurrency limits of Lambda to scale out processing.
Like the other options, integration with Redshift is managed through an external Lambda UDF. This setup ensures that the process remains completely transparent to Redshift users, allowing them to trigger complex parallel tasks from within Redshift using SQL, without needing to be aware of the underlying orchestration.
Pros:
- Minimal Additional Code: This approach requires almost no additional code for the “worker functions” since the same Lambdas used in previous setups can be repurposed for parallel execution.
- High Horizontal Scalability: The system can scale horizontally with Lambda’s concurrency limits, making it ideal for tasks that can be parallelized to process large amounts of data simultaneously.
- Transparency: From Redshift’s perspective, the entire process remains completely transparent, with no noticeable difference in the user experience compared to other solutions.
Cons:
- Orchestration Complexity: One of the main challenges is the need to write an “orchestration” function that monitors and manages the execution of multiple Lambda functions, ensuring that all tasks are completed before proceeding.
- Additional Complexity with SQS: Introducing SQS into the architecture adds complexity. This may require additional setup and monitoring, increasing the operational overhead.
- Costs: SQS potentially generates additional costs. However, since a million requests cost less than 50 cents, it is likely that the service does not become a significant cost factor in this solution. More importantly, the architecture may lead to a much larger number of lambda invocations. The trade-off between shorter runtime and additional invocations should be closely monitored.
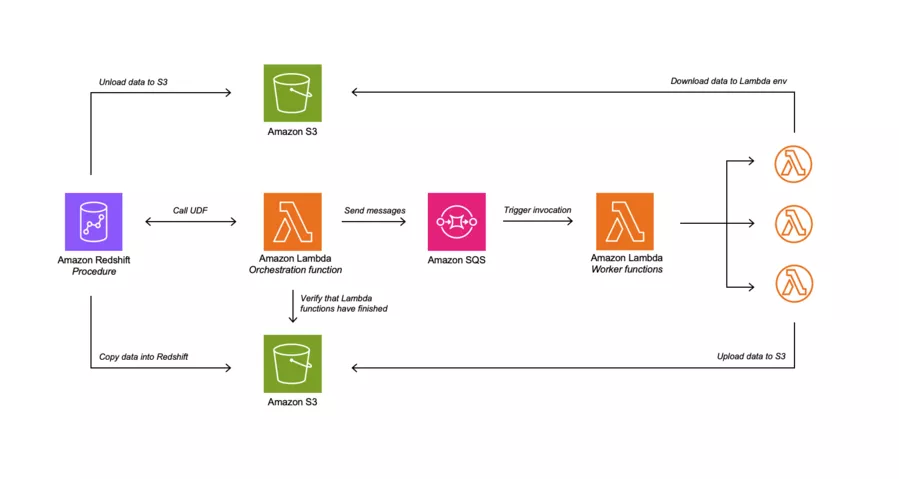
Solution 3
This option can best be leveraged if the task at hand is well-suited to be executed concurrently in independent runtimes. If the task requires that all data be processed in one invocation, the architecture will not help improve performance compared to using a simple Lambda UDF. In that case, it might be better to consider option 2, i.e., AWS Fargate.
The best solution for your team?
In choosing the best architectural approach, it's essential to weigh the specific needs of your team against the capabilities and limitations of each option. To guide this decision, consider the following key factors:
Need for Flexibility
If your tasks require flexibility while avoiding the added complexity of Docker, Lambda UDFs are the ideal choice. They allow you to seamlessly integrate various programming environments directly into Redshift, offering a straightforward, serverless solution that balances ease of use with sufficient power for most scenarios. If your deployment package is sufficiently small, you may even be able to deploy the function without using the additional complexity of Docker.
Execution Speed
When execution speed becomes a critical factor, consider whether your tasks can be parallelized. If they can, leveraging SQS to manage parallel Lambda executions will allow for high horizontal scalability. If parallelization isn’t possible and you encounter Lambda’s runtime limit, AWS Fargate offers a way to overcome this by scaling up compute power, though it may still be constrained by the 15-minute limit imposed by the Lambda UDF orchestrator.
Compute Power
if your applications demand more flexibility than Lambda can offer, or if you're facing tasks that require heavy computation, AWS Fargate is a natural step up. It provides scalable compute resources with the added benefit of customizable environments, although this comes at the cost of increased complexity in management.
If the solutions proposed here do not fulfill your requirements, the AWS platform offers numerous alternatives to extend Redshift’s data processing capabilities even further (e.g. circumventing the 15-minute limit by leveraging asynchronous function calls instead of relying on synchronous Lambda UDFs), usually at the cost of additional complexity. Ultimately, the choice of architecture should be driven by the specific demands of your data processing needs. Evaluate your current workload and future requirements to determine which option will best enhance your Redshift environment.
If you are not sure yet, start with creating Docker images even for a simple Lambda-function. This provides you with full flexibility as it will make it easier to switch from Lambda to AWS Fargate if necessary.
Want to spar?
Are you facing exactly this challenge and need a good sparring partner? Or support with the implementation? Then get in touch with us at any time. Our data professionals are looking forward to your project!
Your contact: Timo Böhm