







Polars: develop faster, execute faster
Polars, the Pandas challenger written in Rust, is much faster, not only in executing the code, but also in development. Pandas has always suffered from an API that "grew historically" in many places. Polars is completely different: it ensures significantly faster development, since its API is designed to be logically consistent from the outset, carefully maintaining stringency with every release (sometimes at the expense of backwards compatibility). Polars can often easily replace Pandas: for example, in Ibis Analytics projects and, of course, for all kinds of daily data preparation tasks. Polars’ superior performance is also helpful in interactive environments like Power BI.
Polars plugins: an underestimated resource
Although Polars is relatively new, a small set of plugins is already available. One of them is particularly useful in a situation in which I wish to find all bus stops within 500 m from a subway stop. First, the geographical location of each bus and subway stop is stored in a DataFrame. This leads to a Cartesian product (cross join) between the two DataFrames, which is then filtered by applying the distances between the subway and bus stops.
Cartesian products become very large, even with moderate-sized DataFrames. Therefore, it’s important to subsequently filter the data efficiently to allow most of them to be discarded. This calls for rapid computation of the geographical distance between two points. For us, the haversine formula is adequate for calculating the distance between two points on earth, based on the mean spherical radius of the earth. Although the earth is not quite spherical, but flattened at the poles and somewhat irregular like a potato, this approximation is accurate enough for most applications. Python has packages for this, but the calculation is unfortunately extremely slow for Cartesian products.
Polars-distance saves the day
Luckily, the Polars plugin polars-distance by Ion Koutsouris implements this function in Rust, making it directly accessible in Polars. Compared to a Python implementation, the plugin improves performance enormously.
An example: I was recently tasked to go through the more than 8,000 postal codes in Germany, and to find all codes with a center point within a defined maximum distance. I first tried the Python variant, using an admittedly somewhat more precise and complex approximation of the distance – the geodesic function from geopy. However, I aborted the execution after 20 minutes, because this was way too slow. Polars-distance, on the other hand, did the whole thing in two seconds flat. Figure 1 illustrates the result: all postal codes shown in yellow are less than 30 km from the center of Bremen City (postal code 28203, the small orange spot in the middle).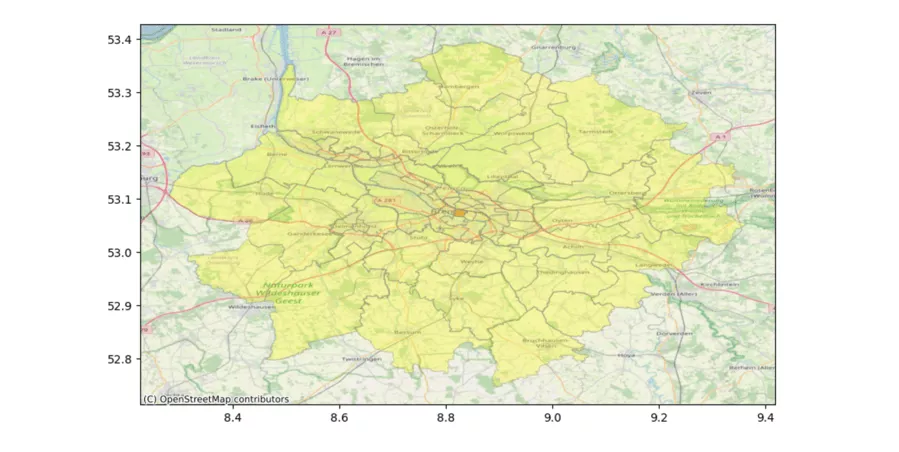
Figure 1
Time for some code
What does the join for the postal code example actually look like? Let's assume that our postal codes are in the Polars DataFrame "postcode2center", which has a string column ("postcode") with the postal code and a column "center" containing the longitude and latitude of the center of the postal code area. The column "center" is a polars Struct with two float64 fields – "latitude" and "longitude". The maximum distance we are willing to accept is in the variable "radius_km".
At the very beginning (".lazy()") and at the very end (".collect(streaming=True)"), we use another Polars feature that Pandas lacks: the lazy API. This ensures that the process does not blow up in our faces, even if our main memory is inadequate for the more than 64 million rows of the Cartesian product. The use of polars-distance (which we have imported here as pld) is then quickly done in the line that starts with ".with_columns". A new column with the name "distance_km" is created there, which we use in the filter in the next line. We could also merge assignment and filtering into a single command, but it is easier to read this way. In the end, we get a DataFrame with the string column "postcode" and a column "postcodes_within_radius", which contains the surrounding postal codes as a list of strings.
Polars-distance: not just for geodata
This plugin is useful for more than just geodata. For instance, you can solve a similar problem in which you wish to identify all fields with the similar spelling within a list of free-text fields. Here, you must filter a Cartesian product quickly using a distance function. Polars-distance computes the Levenshtein distance, which was invented for such text operations. Polars-distance also provides some variations of the Levenshtein distance, and some distances for other kinds of applications as well, for example for the list datatype. The complete list (no pun intended) can be found in the documentation. So, if you ever need to determine distances again, check first if polars-distance can do it! And, if you’re unsure of how to transition from Pandas to Polars in your company, don’t hesitate to contact us – we’d be happy to help.

