







Architecture recommendations and data-processing techniques with Azure Synapse Analytics. This article of ours provides two architecture recommendations, besides showing how they can be implemented and how data are provided for visualization.
In addition to data ingestion, data processing in the Industrial Internet of Things (IIoT) is still a major challenge for many companies. How companies successfully implement IoT projects, and what a successful 6-point plan looks like, can be read here. An easy start in connecting industrial devices to the cloud has been described here. Also shown is how IoT Central can be used to read an industrial robot's data from an OPC-UA server and deposit the data using Azure Blob Storage.
Industrial demand for cloud computing platforms such as Microsoft Azure is growing steadily. The resultant scalability and available IoT stack allow rapid ingestion, processing and analysis of industrial data from sources such as SCADA, as well as connection of different ERP & MES systems.
Azure Synapse Analytics
Microsoft Azure offers numerous services for processing IoT data. The architecture recommendations in the second section are based on Azure Synapse Analytics, a central analytics platform which combines data ingestion, processing, storage and visualization. In addition to (near) real-time data processing using Spark Pools and Synapse Notebooks, there is also a possibility of batch processing by means of Synapse Pipelines. Another advantage is integration with Azure Data Lake storage, as well as saving of data in delta format. Processed data can subsequently be visualized in combination with direct Power BI.
There are also further services allowing IoT data processing. These are discussed in the second blog article of this series of ours. We describe data processing with Azure Stream Analytics, and a serverless variant with Azure Functions.

Batch processing with Azure Synapse Analytics
Data saved using blob storage are loaded, transformed, and written to Azure Data Lake Storage Gen2 via Azure Pipelines. The pipeline created for this purpose contains two central functions. Firstly, columns must be converted to the correct data types; secondly, the JSON string column must be parsed. By means of a provided parseJson function, nested columns are extracted and inserted as individual columns into the data set.
The transformed data are stored in Azure Data Lake Storage, and made available for visualization using Synapse.


Finally, Azure Dedicated SQL Pool makes it possible to create a Power BI data set via a view of the data lake, and continuously update reports. A pipeline trigger can be selected in the management section of Azure Synapse Portal. A time schedule must be set there specifically for each case of batch processing.
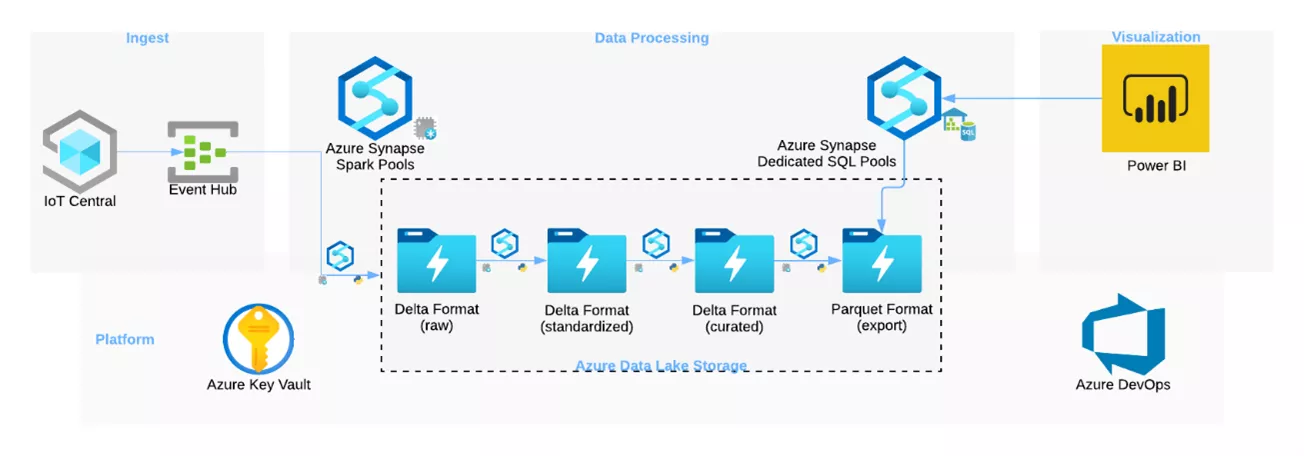
(Near-) real-time processing with Azure Synapse Analytics
As an alternative to batch processing, data in this use case are forwarded to Synapse via Azure event hubs. Data processing takes place with the help of Spark Streaming and Azure Spark Pools, and is divided into various stages. A central service here is Azure Data Lake Storage Gen2 which reproduces the write-once, access-often analytics pattern in Azure. The employed storage format is delta, which offers higher reliability and performance for all data sources stored in ADLS, and is therefore very suitable for IoT data processing.
In ADLS, data are divided into different layers:
- Raw: Raw data are stored in delta format, and neither transformed nor enriched.
- Standardized: Data are stored in a standardized format with a clear structure.
- Curated: Data are enriched by means of further information.
- Export: Data are prepared for export and further processing.
The final export layer is required due to the still existent limitation of external tables with Azure Synapse Dedicated SQL Pools which are not able to read the delta format (Azure documentation).
Connections between event hubs and ADLS Gen 2 are established using Spark Streaming. A prerequisite for this is provision of an access token in Azure Key Vault, and queries using mssparkutils.

Further transformation and enrichment of data are also carried out with Spark Streaming. For this purpose, the JSON string column in event-hub data is first extracted and divided into individual data columns. After this standardization, further KPIs are calculated and the final data set is saved.
The enriched data are queried using a Synapse Dedicated SQL Pool, and made available in an external table for Power BI. The stored table is updated in (near) real-time and enables corresponding insights into the industrial robot's current data.
Outlook
In the next article, we will discuss two more architectures related to IoT data processing. We will show how to implement these using Azure Stream Analytics and Azure Functions. Afterward, we will also take a closer look at the Power BI dashboard for data visualization, and present the result of end-to-end data processing with the recommended Azure architectures.
Are you not sure whether your organization is ready for IoT? Then take an IoT readiness check here!
Or just contact us directly!