







General requirements of enterprises
Many companies with SAP source systems are familiar with this challenge: They want to integrate their data into an Azure data lake in order to process them there with data from other source systems and applications for reporting and advanced analytics. The new SAP notice on use of the SAP ODP framework has also raised questions among b.telligent's customers.This blog post presents three good approaches to data integration (into Microsoft's Azure cloud) which we recommend at b.telligent and which are supported by SAP.
First of all, let us summarize the customers' requirements. In most cases, enterprises want to integrate their SAP data into a data lake in order to process them further in big-data scenarios and for advanced analytics (usually also in combination with data from other source systems).
Of course, the most important requirement is an absence of performance problems and failures on the part of the source system. In other words, the source system must never be overloaded. For reporting and analytics, many enterprises consider an availability of data valid the day before to be sufficient. Only in rare cases must an availability of more recent data be ensured. It is therefore usually sufficient to load the latest data into the data lake every day via daily batch jobs.
In order to significantly reduce data quantities, costs and system loads, the daily loads should ideally dispense with a full reading of all relevant tables. Depending on the source system, however, the details of this issue can be challenging. One of the most important requirements on the business side is usually for data to be available reliably and efficiently for reporting no later than during office hours. It is therefore important for jobs to be executed ideally at night with a sufficient buffer.
An important requirement from the IT perspective is for the solution to be easily maintainable and extensible. This necessitates transparent monitoring of jobs and automated alerting. In detail, there may be further technical requirements, for example, in the area of data-storage formatting and partitioning.
General overview of proposed solutions
With regard to our SAP data extraction scenario, 2024 saw a significant update to SAP notice 325574, which understandably worries our customers. The new policy states that use of the RFC modules of the operational data provisioning (ODP) data replication API by customers' or third-party applications to access SAP ABAP sources is no longer permitted. To alleviate our customers' worries, we can offer three smart solution variants which SAP continues to support and which are often used by customers to integrate SAP data. As already mentioned, the "right" variant in each case depends on the customer's initial situation and requirements. Provided next is an overview of the three variants with their core characteristics:
SAP Datasphere
Datasphere is a SaaS cloud service of the SAP business technology platform for collection and provision of enterprise data. With its possibilities for modeling, connecting and virtualizing SAP and non-SAP data, it plays a central role in the current SAP data management strategy.
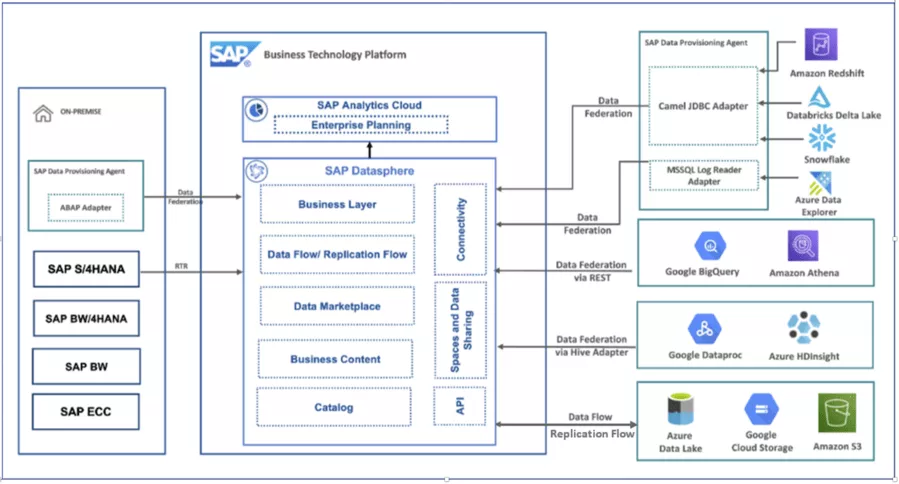
Figure 1: Solution diagram - Datasphere (reference): SAP Discovery Center Mission - Explore your Hyperscaler data with SAP Datasphere (cloud.sap)
Premium outbound integration is SAP's preferred and recommended way to transfer SAP data to a data lake. With the help of replication flows, SAP source data can be connected to the datasphere in a CDC-compatible manner and made available directly in the data lake as parquet files. CDS views with delta capability are also supported as a source.

Figure 2: Connectivity options - SAP Datasphere replication flows
For details on using replication flows, see also Replication Flow Blog Series Part 2 – Premium Outb... - SAP Community.
A clear advantage of this solution is that it follows the current SAP strategy for such scenarios and can therefore also be expected to receive future SAP support. Integration of Datasphere with SAP sources is already well supported and we can expect further innovations, for example, in terms of interaction with hyperscalers and SAP partners. Data loading times with this option are relatively good. Another advantage: The CDS views as a semantic layer are already integrated into the business content delivered as standard. If necessary, data can be transformed or modeled during extraction or subsequently in Datasphere. Here, too, business content is already delivered.
Datasphere service costs follow a subscription model, as is generally the case with business technology platforms. Also to be noted is that data extraction and provision are orchestrated via the Datasphere, so that a push principle is employed from the Azure perspective.Depending on how an enterprise is organized, this can result in a transfer of responsibilities (SAP – Azure).
Azure Data Factory
Microsoft's Azure Data Factory is an Azure solution for batch integration of source-system data. The solution offers connectors for many different source systems, including SQL Server, Oracle, Dataverse, and SAP. A choice of basic connectors is available for SAP (e.g. SAP Table, SAP HANA and SAP CDC). The connectors differ in terms of access to data (access to ABAP layers or directly to HANA DB), and accordingly there are also differences in the associated license agreements, functionalities and performance. Before we go into the specific differences between the individual connectors, it is important to briefly describe how these connectors can be used:
The connectors are controlled by parameters which can be defined in the user interface of the Azure Data Factory. Basically, these parameters must be used to define appropriate connection details to the source system, such as source-system address, user and credentials, as well as information about the transfer destination and the file format in which data are to be stored.
At the table level, it is necessary to specify which table is to be read. In detail, it is possible to control further parameters such as partitioning and the type of insert during writing of data. Data extraction via connectors can then be organized and orchestrated via the ADF pipelines.
It is not advisable to manually define connector parameters via hard-coded values per table. That's why b.telligent has established its own metadata framework for practical use of the connectors. The objective here is avoidance of hard-coding of the above-mentioned parameters for the connectors, and instead reading from a config metadata table. The secrets for accessing the source systems are read from the key vault. This "metafactory" framework allows data integration to be easily and securely extended to include additional tables as required. For example, if the business needs another SAP table for reporting purposes, an internal developer can expand the metadata table accordingly.
As already mentioned, a choice of SAP connectors is available in the ADF. We will now examine the main differences between the ADF-SAP connectors; specific details can be found in Microsoft's documentation.

Figure 3: Overview of Azure Data Factory connectors
Our experiences with Azure Data Factory (ADF) have been very positive. We have already built several productive pipelines with the ADF connectors. A major advantage is that ADF not only offers SAP connectors, but also options for connecting many other data sources. This allows enterprises to implement uniform data-integration processes.
In terms of performance and stability, we have been able to meet core requirements and have had good experiences under standard general conditions. This applies provided that the solution has been implemented correctly. However, there are also disadvantages, especially in terms of user-friendliness for developers in the SAP context. For example, some connectors from ADF do not allow queries of the number of rows in a table, nor do they provide any information about the fields of the SAP tables. This is particularly tedious when planning initial loads, because table sizes need to be correctly classified in advance. Here we advise working closely with developers who have the necessary knowledge of the SAP source system to be able to obtain the appropriate information from the system when needed.
Another point is that the current ADF connectors do not allow change data capture (CDC) (as of October 2024). However, CDC is often important for loading certain SAP tables incrementally, especially if no unique departmental timestamps or IDs are available for proper incremental loading. Before using an ADF connector, it is therefore essential to check whether all tables can also be loaded without the CDC offered in the connector.
Third-party providers
Among third-party providers, Theobald Software from Stuttgart is probably the best-known and most used tool in Germany. We will therefore go into more detail about this tool here. In general, there are a number of third-party solutions, which we will consider in a later blog.
Theobald Software has two main products for extracting data from SAP. XtractUniversal (XU) - a stand-alone solution - as well as an add-on Xtract IS (for Azure) for Microsoft's SQL Server Integration Services (SSIS).
1. Xtract Universal (XU) is the newer product, and consists of an application server which executes the extractions, as well as a GUI - the XU Designer - for defining the extractions, including destinations, without any need for programming. The designer provides the following functionalities:
- Search field for seeking SAP objects
- Metadata concerning columns, such as description, primary key, etc.
- Filtering options
- Row count and row preview of data
- Access restrictions
- Log viewer
Extractions can be performed either manually via Designer or via a command-line call / API call. The latter offers the possibility to store control parameters for extractions (time-based and parallel/serial) in a metadata framework of all cloud providers. All known databases and blob storages are available as destinations for an extraction. In addition, there are also pull-destinations such as Power BI connectors.
2. Xtract IS (for Azure) is an add-on for SQL Server Integration Services (SSIS) allowing SAP data to be used as dataflow sources. Consequently, this product only works in conjunction with SSIS. It is the older product, and will be treated as a secondary option in further developments. Newer features or components are therefore first included in the "Xtract Universal" product, and integrated here later. The respective interface components have the same functionalities as the XU Designer.Only logging has to be handled via the SSIS. In this context, see further above. For this product to work in the Azure cloud, SSIS IR must be used and customized.
This solution is well suited for lift & shift scenarios, but also for new developments if an application server is not to be used for extraction. The SSIS are an extension of Visual Studio and can therefore be used for development free of charge. Here, however, one is bound to Microsoft and SSIS.
Possible SAP extraction objects in the case of both products include transparent tables, cluster tables and views, all of which can be filtered and parameterized. The TableCDC component allows delta extraction of a table if no delta can be determined on the basis of a specific column. The ODP component, on the other hand, allows extraction of all objects made available by SAP via ODP. This component is currently not recommended though. In future, however, it will be offered with an ODATA variant in order to comply with SAP's release notice 3255746. Other extraction objects are BAPI, RFC function modules, SAP ERP queries, SAP data sources, SAP CDS views, BW/4HANA objects, BW hierarchies via open hub services, as well as cube objects from BW/BW Hana and ABAP reports.
Version control / deployment
The XU product and the solution (Visual Studio) [SSIS with extension XtractIS] can be connected to version control such as Git or DevOps, thus allowing deployment in different environments.
License fees
License fees are incurred for both products. The license fees correspond to a subscription model. This means that updates and support from Theobald are available for an annual fee.
Individual components
Shown next is a list of the individual components which can be used to access the corresponding SAP objects.

Figure 4: Overview of Theobald connectors
Conclusion and final evaluation
This blog post has highlighted three different approaches to transferring SAP data to the Azure cloud. The solutions with the Theobald and ADF connectors are very similar in principle. More specifically, the Theobald connectors offer slightly better usability and additional functionalities. License costs are incurred here for the use of Theobald though, and corresponding VMs are needed in the architecture landscape.
SAP Datasphere is SAP's official recommendation for exporting SAP data, so you can expect further innovation and SAP support here.However, it is worth mentioning that not all companies use Datasphere, which in turn requires SAP know-how for implementation. In addition, the overall process can entail a transfer of responsibility. Details are provided in the section on Datasphere.
This closes the circle. Ultimately, the best solution depends decisively on the customer's situation. Simple scenarios involving small- to medium-sized amounts of data and minor changes in requirements certainly need different variants compared with highly complex scenarios.
Do you have the same challenge?
If you are also facing the challenge of integrating SAP data into a cloud data lake, please get in touch with us. Our experts will provide you with friendly and competent support and the relevant know-how!